| Category | Benchmarks | Key Insights |
|---|---|---|
| General Language Understanding | GLUE | Diverse set of tasks for evaluating general NLU |
| SuperGLUE | More challenging successor to GLUE | |
| MMLU | Tests knowledge across 57 subjects | |
| Question Answering | SQuAD | Evaluates reading comprehension on Wikipedia articles |
| NaturalQuestions | Uses real Google search queries | |
| TriviaQA | Tests ability to answer trivia questions | |
| HotpotQA | Requires multi-hop reasoning across documents | |
| CommonsenseQA | Focuses on common sense reasoning | |
| CoQA | Measures conversational question answering ability | |
| Machine Translation | BLEU | Standard metric for evaluating translation quality |
| WMT | Annual competition for machine translation systems | |
| Text Summarization | ROUGE | Set of metrics for evaluating automatic summarization |
| CNN/Daily Mail | Large-scale dataset for news summarization | |
| XSum | Tests ability to generate highly abstractive summaries | |
| Common Sense Reasoning | HellaSwag | Tests for situational common sense understanding |
| Winograd Schema Challenge | Evaluates pronoun resolution abilities | |
| Winogrande | Larger and more diverse version of Winograd | |
| SWAG | Multiple choice task for grounded common sense inference | |
| COPA | Evaluates causal reasoning in everyday situations | |
| Reading Comprehension | RACE | Large-scale reading comprehension dataset from English exams |
| LAMBADA | Tests understanding of broad contexts | |
| ARC | Challenge set of grade-school science questions | |
| Truthfulness / Fact Verification | TruthfulQA | Measures tendency to generate truthful statements |
| FEVER | Evaluates claim verification against evidence | |
| Multi-task / Diverse Skills | BIG-bench | Large-scale, diverse benchmark with 204 tasks |
| Natural Language Inference | XNLI | Multi-language version of NLI task |
| MultiNLI | Diverse NLI dataset across genres | |
| ANLI | Adversarially-constructed NLI dataset | |
| Social and Situational Understanding | SocialIQA | Tests reasoning about social situations |
| Complex Reasoning | DROP | Requires discrete reasoning over paragraphs |
| Paraphrasing / Textual Similarity | PAWS | Focuses on high lexical overlap paraphrases |
| STS | Measures semantic similarity between sentence pairs |
| Category | Benchmark | Description |
|---|---|---|
| General Language Understanding & Reasoning | GLUE | A collection of diverse NLP tasks to assess overall understanding. |
| SuperGLUE | A more challenging successor to GLUE, pushing the boundaries of NLU. | |
| MMLU | Tests knowledge and reasoning across 57 diverse tasks, offering a broad evaluation. | |
| MMLU-Pro | A more difficult version of MMLU, focused on professional and specialized knowledge domains. | |
| Question Answering | SQuAD | Evaluates the ability to answer questions from a given text passage. |
| ReCoRD | Focuses on reading comprehension that requires commonsense reasoning. | |
| BoolQ | Tests the accuracy of answering yes/no questions from a text. | |
| DROP | Evaluates the ability to perform discrete reasoning over paragraphs to answer complex questions. | |
| QuAC | Tests conversational question answering, where context from previous turns is important. | |
| RACE | Evaluates reading comprehension using challenging questions from English exams. | |
| OpenBookQA | Tests reasoning ability when given access to a relevant knowledge base. | |
| HotpotQA | Requires multi-hop reasoning, where answers are found by combining information from multiple sentences. | |
| TriviaQA | Focuses on answering open-domain trivia questions using general knowledge. | |
| NaturalQuestions | Uses real user questions from Google search, reflecting real-world information needs. | |
| Reasoning & Commonsense | CommonsenseQA | Evaluates the ability to answer questions that require common sense knowledge. |
| Winograd Schema Challenge (WSC) | Focuses on resolving pronoun ambiguities, a challenging aspect of commonsense reasoning. | |
| Winogrande | A larger-scale version of the Winograd Schema Challenge. | |
| HellaSwag | Tests commonsense inference by choosing the most plausible continuation of a story or scenario. | |
| ARC (AI2 Reasoning Challenge) | Evaluates science question answering, demanding complex reasoning skills. | |
| COPA (Choice of Plausible Alternatives) | Tests the ability to choose the most plausible cause or effect given a premise. |
Why we need those LLM Evaluation Metrics ?
Large Language Models have made a notable presence in the AI sector, showcasing their conversational skills, text generation capabilities, and coding abilities. Yet, as we consider their sophisticated language processing abilities, one crucial inquiry emerges: How can we accurately assess the full capabilities of these powerful AI systems? The solution can be found in the frequently ignored realm of LLM benchmarks.
Assessing LLM necessitates a clever strategy that includes utilizing several criteria. These benchmarks help us reveal the genuine strengths, weaknesses, and potential of LLMs by going beyond surface-level evaluations.
Unveiling True Potential: Why Benchmark Diversity Matters
Evaluating LLMs requires a diverse toolkit of benchmarks. Like we humans can not be good in all fields , LLMs can not master everything too. It is all about your purpose and your expectation from that person (now LLM wow 🙂 : If you need an engineer you might want to evaluate your candidate with math questions , if you need a teammate in social branches , you would probably prepare or use an emotional intelligence assessment. This is nothing but same in LLM Benchmarks , stakeholders come and say I need the best performing LLM in summarizing long texts logically , but the model can be stupid in common-sense no problem! You say : ROUGE would be good metric for your aim. By leveraging a diverse range of benchmarks covering various aspects of language processing and comprehension, we can gain comprehensive insights into the desired strengths and potential undesired harmful behaviors of LLMs.
Let’s take a look at some key categories and explore how specific benchmarks can help us to understand what the model can do and therefore maybe next time build better LLM:
1. Testing Foundational Language Skills:
These benchmarks assess core language comprehension and generation abilities—essential building blocks for any LLM aiming to interact meaningfully with the world:
MMLU: The Academic Measure for LLMs
This benchmark adopts a broad methodology, assessing an LLM’s expertise in a variety of fields, including the social sciences, history, STEM, and more. Comparable to an extensive general knowledge exam, it evaluates the depth and breadth of an LLM’s knowledge in a variety of subject areas. This extensive exam assesses an LLM’s knowledge in 57 different areas, ranging from computer science and law to elementary math and US history. A high MMLU score indicates a strong general knowledge base. Envision an AI decathlon that assesses proficiency in multiple fields. The Massive Multitask Language Understanding (MMLU) benchmark essentially accomplishes that.Multiple-choice questions from a variety of fields make up MMLU. The AI model is provided.And the results are compared with the real answers.
Why does MMLU matter?
MMLU gives us insight into an AI model’s ability to handle a range of subjects. It’s analogous to evaluating the AI’s educational background. This is important because, rather than having AI systems that are experts in a single field, we want them to be able to help with a variety of tasks.
As an illustration
Suppose we have a query from the History section:
Who was first president of USA ?
A) Thomas Jefferson B) George Washington C) Benjamin Franklin D) John Adams
Option A would have to be chosen by the AI model. We estimate the model’s general knowledge capabilities by examining its performance on thousands of such questions across various subjects.
MMLU’s limitations
Even though MMLU is excellent at giving a general picture of an LLM’s capabilities, it’s important to understand its limitations. Because the questions are artificial, they may not accurately capture the complexities of language use in everyday situations, and depending only on multiple-choice accuracy may obscure some crucial aspects of a model’s comprehension.
GLUE and SuperGLUE for Challenging the Language Understanding
Consider GLUE (General Language Understanding Evaluation) and SuperGLUE (a more difficult version) to be the SATs of the LLM domain. These benchmarks assess fundamental abilities related to language comprehension, such as question answering, sentiment analysis, and textual entailment.
What tests do SuperGLUE and GLUE cover?
These benchmarks comprise the following tasks:
Sentiment analysis: Identifying the emotional tone behind the text, in most cases classifying the Sentiment as positive or negative.
Textual entailment: Determining if one statement logically follows from another. “The cat sat on the table” implies “The table is also under the cat.” And the (relative) position of the table should be understood by the model.
Answering questions: Determining the right response to a query using a provided text
Why do they matter?
By using GLUE and SuperGLUE , we may evaluate how well the LLM comprehend language nuances rather than just words or basic information. This is essential for developing more advanced Language models that can interact with us more meaningfully , more human like , naturally.
- SQuAD (Stanford Question Answering Dataset): Zeroing in on the crucial skill of question answering, SQuAD tasks LLMs with finding precise answers within large chunks of text. This is critical for applications like virtual assistants and chatbots that must sift through mountains of data to answer user queries accurately.
- Example: A user asks a smart speaker powered by an SQuAD-trained LLM, “What is the tallest mountain range in the world?” The LLM successfully pinpoints the answer—the Himalayas—from a vast pool of information.
- How does SQuAD work?
- The benchmark provides a passage of text and a related question. The AI model must identify the specific portion of the text that answers the question.
2. Navigating the World with Commonsense Reasoning:
Commonsense reasoning, something we humans often take for granted, has proven to be a stumbling block for LLMs. These benchmarks focus on closing that gap:
- WinoGrande: Picture this: “The trophy doesn’t fit in the brown suitcase because it’s too _____”. Instinctively, humans know the missing word is likely “big” or “large” based on our understanding of size and spatial relationships. WinoGrande challenges LLMs with similar common-sense scenarios, evaluating their ability to “think” logically and make inferences about the world around them.
- HELLASWAG (HellaSwag is a Stereotype Benchmark!): This benchmark injects a healthy dose of humor and real-world situations into the evaluation process. LLMs face a multiple-choice dilemma, choosing the most plausible continuation for a given scenario. For instance, it’s more likely that someone will spill coffee on their keyboard than successfully juggle flaming torches while riding a unicycle. Success here indicates an LLM can distinguish between plausible and outlandish scenarios.
3. Venturing Beyond Text: Multimodal Understanding:
Our world isn’t just about text; it’s a rich tapestry of visual information as well. These benchmarks evaluate how well LLMs connect language with what they “see”:
- COCO (Common Objects in Context): Though primarily associated with computer vision, COCO plays a vital role in assessing the multimodal capabilities of LLMs. Imagine challenging an LLM to generate an accurate caption for a photo of a bustling city street, answer questions about the objects within the scene, or even tell a story inspired by a single image. This benchmark evaluates how effectively LLMs integrate visual and textual information—a crucial step towards building AI that perceives and interacts with the world more like we do.
4. Capturing the Art of Narrative and Creativity:
While quantifying creativity is no easy feat, these benchmarks provide valuable insights into an LLM’s ability to generate text that flows, engages, and sparks imagination:
- LAMBADA (Language Modeling Broadened to Account for Distant Anaphora): This benchmark dives into the intricacies of storytelling and narrative comprehension. LLMs face the challenge of predicting the next word in a sentence, considering not just the immediate context but also the broader narrative flow. A successful LAMBADA performance suggests an LLM can grasp the subtle nuances of storytelling and maintain coherence over longer stretches of text, a crucial skill for tasks like generating compelling narratives.
Looking deeper than just the numbers: Moving towards evaluation with significance.
Assessing LLMs is a continuous process, and the benchmarks we have looked into are merely the beginning. As LLMs develop, the tools and metrics for evaluating their progress will also advance. The aim is not just to pursue better scores but to acquire a detailed comprehension of the functioning of these advanced technologies, how we can use them efficiently, and importantly, how to reduce possible biases and risks in the process. The development of AI in the future hinges on our dedication to responsible practices, and benchmarks will play a crucial role in guaranteeing that AI benefits humanity genuinely.
Large Language Models (LLMs) such as ChatGPT have been gaining attention for their remarkable abilities in generating text and understanding language. However, under the facade of these seemingly sophisticated AI models is a machine learning algorithm that has been trained on extensive datasets. So, how can we see past the exaggerated claims and accurately evaluate the abilities of these AI inventions? The solution can be found within LLM benchmarks – tests created to challenge these models and reveal their genuine strengths and weaknesses.
In this blog post, we will examine key assessment measures and standards utilized to evaluate LLMs. If you are interested in AI or want to learn about how we evaluate the effectiveness of language models, you are in the correct location.
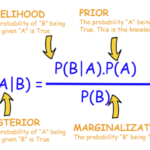
Human Evaluation: The Gold Standard
While automated metrics are useful, they can’t capture all aspects of language quality and usefulness. That’s where human evaluation comes in.
How does Human Evaluation work?
Typically, human evaluators are given specific criteria and asked to rate or compare AI outputs. This might involve:
- Scoring responses on a scale (e.g., 1-5 for accuracy)
- Comparing outputs from different models
- Answering yes/no questions about the AI’s performance
- Providing detailed feedback on strengths and weaknesses
Why is it important?
Human evaluation can capture nuances that automated metrics might miss, such as contextual appropriateness, creativity, logical coherence, and emotional impact.
WinoGrande: Testing Common Sense
WinoGrande focuses on commonsense reasoning – that elusive human ability to understand implicit meanings and make logical connections. It throws tricky pronoun resolution tasks at LLMs, forcing them to rely on contextual clues and world knowledge to decipher meaning.
Example
Consider this sentence: “The trophy doesn’t fit in the suitcase because it’s too big.”
What does “it” refer to – the trophy or the suitcase? Humans can easily infer that “it” refers to the trophy, but this type of reasoning can be challenging for AI models.
BLEU: Measuring Translation Quality
If you’ve ever used an online translator, you’ve benefited from AI language models. But how do we know if these translations are any good? Enter BLEU score (Bilingual Evaluation Understudy).
How does BLEU work?
BLEU looks at the overlap of words and phrases between the AI translation and one or more reference human translations. The more overlap, the higher the score.
Why is it important?
Translation is a key application of language AI. BLEU helps us compare different translation models and track improvements over time.
Example
Let’s say we’re translating a French sentence to English:
Original (French): “Le chat dort sur le canapé.”
Human reference: “The cat is sleeping on the couch.”
AI translation 1: “The cat sleeps on the sofa.”
AI translation 2: “A cat is napping on the couch.”
BLEU would give a higher score to AI translation 1 because it has more word overlap with the human reference. However, it’s worth noting that AI translation 2 is also correct and natural-sounding, which highlights some limitations of BLEU.
ROUGE: Evaluating Text Summaries
In our information-packed world, the ability to summarize text is incredibly valuable. ROUGE (Recall-Oriented Understudy for Gisting Evaluation) helps us measure how well AI models can create summaries.
How does ROUGE work?
ROUGE looks at the overlap of words and phrases between the AI summary and one or more reference summaries written by humans. It has several variants that focus on different aspects, such as word overlap (ROUGE-N) or the longest common subsequence (ROUGE-L).
Why is it important?
Summarization is a complex task that requires understanding the main points of a text and expressing them concisely. ROUGE helps us evaluate how well AI models can do this.
Perplexity: Assessing Language Predictability
Perplexity might sound puzzling, but it’s actually a key metric for evaluating language models. It helps us understand how well a model predicts language.
What is Perplexity?
In the context of language models, perplexity measures how surprised a model is by new text. Lower perplexity means the model is less surprised and better at predicting language.
Why is it important?
Perplexity gives us insight into how well a model has learned the patterns of a language. It’s particularly useful for comparing different models or versions of the same model.
F1 Score: Balancing Precision and Recall
The F1 score is like the Swiss Army knife of evaluation metrics. It’s used in many AI tasks, especially when we need to balance accuracy and completeness.
How does the F1 Score work?
The F1 score combines two other metrics:
- Precision: How many of the model’s positive predictions are correct?
- Recall: How many of the actual positive cases did the model identify?
The F1 score is the harmonic mean of precision and recall, providing a balanced measure of a model’s performance.
TruthfulQA: Checking AI Honesty
As AI models become more advanced, it’s crucial to ensure they provide accurate information. TruthfulQA is a benchmark designed to test the honesty and accuracy of language models.
How does TruthfulQA work?
The benchmark consists of questions designed to elicit false or misleading answers if the model has learned to reproduce human misconceptions. It covers a wide range of topics, including health, law, finance, and history.
Why is it important?
As we rely more on AI for information and decision-making, it’s crucial that these systems provide accurate information and don’t simply repeat common misconceptions or falsehoods.
Beyond Text: Evaluating Multimodal and Coding Capabilities
As LLMs evolve, new benchmarks are emerging to test their expanding capabilities:
COCO (Common Objects in Context)
COCO evaluates how well LLMs connect visual input with textual descriptions, assessing their ability to generate captions, answer image-based questions, and bridge the gap between seeing and understanding.
OpenAI Codex HumanEval and MBPP
These benchmarks are designed specifically for code-generating models, evaluating their ability to craft correct, efficient, and elegant code across various programming tasks.
In conclusion, assessing language models’ usefulness is a task that composed of multiple efforts with the broad range of metrics and methodologies. TruthfulQA allows you to assess honesty where as MMLU is for academic knowledge.
It’s worth noting that no single metric can paint the picture. The effective assessments typically combine automated metrics with judgment to gain a comprehensive understanding of a models strengths and weaknesses.
As Large Language Models become more integrated into our lives having robust and diverse benchmarks is essential to ensure these powerful tools are developed in an ethical manner. By examining their strengths, weaknesses and potential biases we can leverage the capabilities of these models for purposes while minimizing any associated risks.